История русской локализации Tales of Rebirth (PS2)Глава 9. Создание лок-кита для переводчиков и редакторов (часть 1)https://vk.com/temple_of_tales_translationshttps://temple-tales.ru/games/tor/russian_localization.htmlНаконец-то я подобрался к описанию одного из самых важных аспектов в истории наших локализаций - создания лок-китов. В первую очередь стоит более понятнее объяснить, что же это такое. Лок-кит (от англ. localization kit – «набор локализации») – это специально подготовленный разработчиками набор игровых данных в удобном для взаимодействия виде, которые подлежат локализации на другой язык. В основном эта разработка бывает в виде отдельного программного обеспечения (Memsource), но встречаются и иные проекты на облачной платформе (SmartCAT). В отдельных случаях они могут быть даже в виде таблиц Google. Если говорить простым языком, то это программа для переводчиков, в которой они могут свободно переводить весь игровой текст, учитывая контекст диалогов и различные комментарии от разработчиков, а также видеть любую другую информацию. Если вы попытаетесь поискать какие-нибудь официальные лок-киты в сети, то, скорее всего, ничего не найдёте. Потому что любой лок-кит – это индивидуальная разработка, предназначенная только для внутреннего использования, и к распространению она запрещена. Тем не менее, можно найти несколько скриншотов и хотя бы примерно представить, как выглядят лок-киты у разработчиков:

1)
https://thehouseofthedev.com/materials/itogi-konkursa-pomoshch-v-lokalizatsii-ot-allcorrect-games2)
http://web.archive.org/web/20260123000547/https://thehouseofthedev.com/materials/itogi-konkursa-pomoshch-v-lokalizatsii-ot-allcorrect-gamesЯ тоже захотел сделать что-то подобное для переводчиков и редакторов в своей команде, потому что опыт работы над первым проектом Tales of Symphonia дал чёткое понимание того, что было сделано не так и что именно следует поменять. Поэтому, начиная с Tales of Graces f, я старался делать аналог лок-китов практически для каждого нашего проекта, но объём выполняемых работ был так велик, что в какой-то момент я решил просить помощи и пытался привлечь к их созданию кого-то ещё. Чтобы качество проектов не падало, а создание лок-китов не затягивалось, я сделал себе установку – над лок-китами должны работать только те, кто не будет переводить, редактировать, рисовать, программировать и тестировать. Потому что если привлечь человека, выполняющего любую из этих работ, то гарантировано будет снижаться производительность проекта в целом. Вот к такому разделению задач мы и пришли. Считаю, что это идеальная организация работы – каждый занимается своим делом и никто никому не мешает. Я бесконечно признателен тем, кто в этой затее с лок-китами пошёл мне на встречу. Ведь именно благодаря этим людям удалось значительно ускорить работу над рядом проектов:
@Иван Тырлов (Tactics Ogre Reborn)
@Анатолий Перун (Star Ocean First Departure)
@Викентий Селюцкий (Tales of the Abyss)
@Юрик Машкин (Tales of Destiny PS1)
@Екатерина Αгафонова (Tales of Destiny 2)
@Алиса Суюшева (Tales of Legendia)Сложно подумать, в какой ситуации сейчас была бы наша команда, если бы не их помощь. Многие из них осилили создание лок-кита до самого конца, а кто-то всё ещё находится в процессе работы. Но, как бы то ни было, важно понять, что 1 человек создаёт только 1 лок-кит. Тем не менее, мне самому, как руководителю, тоже приходится заниматься лок-китами для всех остальных игр, с которыми помощи нет. Таким образом я полностью и под ключ осилил создание лок-китов по следующим нашим проектам:
Tales of Graces f (PS3)
Tales of Eternia (PSP)
Tales of Rebirth (PSP)
Valkyrie Profile Lenneth (PSP)Другая часть проектов у меня всё ещё в процессе, а некоторые из них близятся к завершению:
Star Ocean 2 (PSP)
Star Ocean 2 R (PC)
Tales of Phantasia (PS1)
Tales of Symphonia 2 (PS3)
Tales of Destiny DC (PS2)
Tales of Xillia 2 (PS3)Так что же такого важного таят в себе эти лок-киты, что я уделяю им так много внимания? Об этом я хочу рассказать подробно, описав каждое преимущество, так как все они облегчают работу не только с текстом, но и со всем проектом в целом:
а) Хронологический порядок строкЭто, пожалуй, самое главное преимущество, необходимое для полного понимания контекста в процессе перевода. Потому что в неотсортированном виде строки диалогов могут относиться к отдельным локациям. 1 файл – 1 локация. И весь текст, который на протяжении игры отображается в этой локации, будет сгруппирован в одном файле с привязкой к ней. Ещё реже бывают случаи, когда строки располагаются в хаотичном порядке. Стоит ли говорить о том, насколько неудобно переводчику ориентироваться во всём этом? Если человек знаком с сюжетом, персонажами, а ещё лучше, если проходил игру полностью и всё помнит, то это поможет ориентироваться в таком беспорядке. Но как быть тем, кто не знаком с сюжетом и не проходил игру? Именно в таких моментах и будет играть ключевую роль хронологический порядок строк. Это расположение строк сюжетных диалогов, разговоров с НИПами, различных уведомлений и многого другого в том порядке, в котором оно происходит от начала игры и до самого конца, вплоть до титров.
б) Имена и пол персонажейВторое не менее важное преимущество – корректная идентификация персонажей и их пола. Создатель лок-кита проставляет все соответствующие имена в отдельной колонке, напротив строк с диалогами. Так сложилось, что в изначальных дампах текстов далеко не всегда есть информация об именах, а уж тем более о том, какого пола персонаж говорит конкретную фразу. И её наличие помогает избежать лишних проверок и запусков игры. Кроме того, это ещё сильнее позволяет углубляться в понимание контекста, так как в диалогах всегда важно понимать, кто и что сказал – у всех персонажей разный стиль речи и характер, а это играет очень важную роль в процессе перевода текста.
в) Тип строкиПрактически в любой большой игре, помимо сюжетных диалогов и разговоров с НИПами, есть множество других строк с текстом. Это могут быть строки, относящиеся к квестам, дополнительным катсценам, различным уведомлениям, руководствам, хроникам, различным заголовкам и многое другое. Каждый тип строк требует разного подхода в процессе перевода. Например, в уведомлениях или руководствах недопустимо обращаться к игроку на "ты" (за исключением редких случаев). В лок-китах каждый тип строк выделяется визуально или прописывается в отдельной колонке, что тоже очень сильно помогает с определением текста и тем, как с ним работать.
г) МестоположениеЕщё одно значительное преимущество – это знание локации или отдельного места, к которому относится каждая строка. Это очень важная информация, потому что она тоже помогает углубляться в понимание контекста. Переводчику важно знать, где сейчас находятся персонажи: в каком городе, на каком этаже гостиницы или в какой области на карте мира. Данные метки также помогают быстро найти эти строки в самой игре, если требуется оперативно проверить какой-то момент. А ещё знание местоположения персонажей может очень сильно повлиять на сам процесс перевода текста, потому что бывают различные уникальные ситуации, когда кто-то из персонажей на одной из локации ведёт себя как-то иначе в соответствии с задумкой сценариста.
д) Главы, планеты, миры и временные линииВ каждой игре есть свои особенности в плане разделения текста – она может быть разделена по главам или каким-то другим образом. В некоторых играх персонажи путешествуют во времени, а где-то разработчики задумали повествование от лица разных персонажей. Все эти особенности по большей части тяжело как-то отмечать, но в лок-китах это легко решается отдельной колонкой, в которой прописывается, к какой части игры относится каждая строка. Всё это тоже очень важно для переводчика, потому что знание главы может помочь с корректным выражением поведения персонажа в нужном участке времени. Потому что не редки ситуации, когда один из персонажей с какого-то момента начинает вести себя совсем иначе, и это отражается в его речи. Ещё это помогает проверять текст в игре, потому что переводчик, редактор или тестеры будут знать, в каком моменте эта строка появляется. Например, если по сюжету повествование переключается на другого члена отряда и отдельная глава посвящена ему, а при взаимодействии с окружающими НИПами диалоги меняются только в рамках этой главы, то знание этого поможет тщательнее проверять диалоги в игре. К сожалению, когда человек работает с исходным текстом, то все эти моменты отследить очень тяжело, а значит, повышается вероятность совершения ошибок.
е) Графическое выделениеУдобство лок-китов ещё заключается в удобном графическом интерфейсе. Различные выделения всех сегментов очень сильно облегчают ориентацию среди разного типа информации в процессе локализации. Представьте себе ситуацию: сейчас вам нужно перевести только сюжетные диалоги ближайших катсцен, а в первоначальном, неотсортированном виде, в текстовом редакторе эти диалоги визуально сливаются с диалогами НИПов, диалогами из квестов и диалогами из дополнительных сценок. В случае работы с лок-китом переводчику не нужно пытаться как-то распознавать и искать сюжетные диалоги нужных катсцен, потому что они уже отмечены отдельным цветом или иным образом.
ж) Другие языкиВременами в процессе работы могут возникать ситуации, когда нужно оперативно проверить текст требуемой строки на другом языке. Лок-кит позволяет держать рядом несколько колонок на разных языках и постоянно обращаться к любой из них, чтобы проверить нужную информацию. Допустим, у вас под рукой японская, английская, испанская, немецкая и русская колонки с текстом. Если английские локализаторы в чём-то ошиблись, то проверить упущение можно по оригиналу на японском языке. А если возникает спорная ситуации с каким-либо именем или термином, то локализация на другом языке может помочь какой-нибудь полезной идеей, что расценивается как удобная и выгодная находка. Кроме того, если английская локализация отличается своеобразной вольностью, то японский оригинал помогает легче сориентироваться в том, а что же именно разработчики имели ввиду и какая была изначальная задумка, исказившаяся в процессе локализации на другой язык. Ещё стоит отметить такие фонетически подсказки в японском тексте как фуригана. Это даёт дополнительную пищу для размышления в процессе перевода текста.
з) ОзвучкаДиалоги большей части современных игр в жанре японских РПГ практически всегда озвучиваются, что в принципе особо не доставляет каких-либо проблем в процессе перевода текста. Но как быть, если в игре озвучена далеко не вся часть диалогов? Есть очень много игр, где озвучены не все сюжетные кастцены. Одним из таких примеров является Tales of Eternia. В игре озвучены все сценки, а вот сюжетные диалоги – примерно на 1/3. В этом случае метки в лок-ките весьма к месту – в отдельной колонке указано, какие строки озвучены. Это очень важно, потому что интонация и сама манера голоса сэйю может сильно помочь в процессе перевода. Также не редки ситуации, когда текст и озвучка могут отличаться. Всё это хорошо помогает сориентироваться переводчику или редактору для точности перевода, чтобы текст не выбивался за пределы озвучки.
и) Различные особенностиСам процесс перевода текста может иметь различные ограничения или другие особенности. Но как быть, если в отсортированном виде текст не содержит никаких данных по этому поводу? В этом и заключается очередное преимущество лок-китов, потому что здесь можно разместить сколько угодно дополнительных колонок, в которых создатель лок-кита прописывает всю необходимую информацию. Если строка требует особого подхода, например ввод пароля, то этот текст, скорее всего, будет иметь ограничение по количеству символов. Ещё бывают ситуации, когда в определённых строках текст выводится другим шрифтом, и этот шрифт в ресурсах игры имеет только верхний регистр – это тоже необходимо учитывать во время перевода. Количество уникальных ситуаций не счесть, потому что всё упирается в индивидуальные особенности игры. Иными словами, это просто отдельные заметки от разработчиков или создателя лок-кита, которые должны помогать лучше вникнуть в особенность отдельных строк текста.
к) Технические меткиЕсли у вас на руках текст в неотсортированном виде и без каких-либо дополнительных меток, то, скорее всего, вы не сможете нужным образом структурировать различные строки. В таком случае нас спасает очередное преимущество лок-китов – повторюсь, здесь можно сделать сколько угодно дополнительных колонок, прописывать в них различные данные и сортировать по ним весь текст так, как вам удобно. Например, если в игре кто-то из персонажей говорит на другом языке, который как-то особенно оформлен в тексте, а переводчику нужно просмотреть все подобные строки отдельно, то в лок-ките все они легко сортируются нажатием пары кнопок, а затем мгновенно возвращаются на место, потому что каждая строка имеет уникальный идентификатор (ID), с помощью которого всегда можно вернуть первоначальный порядок строк.
л) ГлоссарийОдин из последних и не менее важных плюсов, который стоит упомянуть – наличие глоссария. Многие команды переводчиков сначала прорабатывают именно этот аспект. Постоянный доступ к сформированному списку различных имён, терминов и названий в лок-ките облегчает процесс работы и помогает не нарушать единообразие терминологии. За счёт постоянно доступа обеспечивается связность текста и единый стиль.
На этом, пожалуй, стоит остановиться. Можно долго описывать преимущества лок-китов, ведь всё зависит от разработчиков: чем эффективнее разработка этой уникальной среды, тем быстрее и качественнее будет финальный результат локализации. Я мог бы ещё упомянуть такие дополнительные фичи, как отображение портретов персонажей с разными эмоциями или окно предварительного просмотра того, как будет выглядеть текст в самой игре с учётом подобранного шрифта, но это более глубокие нюансы, которые встречаются ещё реже. Думаю, вы всё больше и больше начинаете понимать, насколько это ценный труд. Всё это, разумеется, очень удобно, и может даже возникать ощущение, что в таком случае практически каждый элемент игры будет под рукой. Но насколько сильно лок-кит ускоряет сам процесс перевода по сравнению с работой в обычном текстовом редакторе? По моим ощущениям – в пределах от 15 до 40%, в зависимости от сноровки переводчика и редактора. Неплохо, не правда ли? Попытаюсь описать все основные моменты, из которых эти цифры получаются и складываются, что в свою очередь продолжает постоянно и стабильно экономить нам время:
а) Уменьшение частых поисков информации и лишних действийНет необходимости часто запускать игру или открывать видеопрохождение, чтобы найти нужный момент и проверить что-либо в зависимости от поставленной задачи. Кроме того, все поиски следующих катсцен или любого другого элемента сведены к минимуму. Потому что все строки расположены в хронологическом порядке и искать ничего не требуется.
б) Исключение проблемы полов, имён персонажей и склоненийПрактически пропадает вероятность ошибиться с именами персонажей, их полом и привязки к строкам. Потому что в документе, в отдельной колонке, напротив строк с диалогами проставлены все имена. Зачастую при работе в обычном текстовом редакторе в исходном тексте могут отсутствовать метки имён персонажей или НИПов. Бывают случаи, когда рядом с сюжетными строками есть дополнительные строки с именами, но в строках, относящихся к НИПам, они отсутствуют. Это приводит к тому, что переводчик может неверно указать склонения различных слов, как того требует пол персонажа. Возможны и другие ошибки, связанные с неверной идентификацией персонажа, что ведёт за собой деформацию его характера, изначально задуманного разработчиками.
в) Облегчение тяжёлой навигации и слабых ориентировНавигация по всему лок-киту становится в разы легче благодаря множеству разных меток, отличающихся как цветом и жирностью букв, так и различными выделениями фонов. Работа в текстовом редакторе неудобна тем, что восприятие текста усложняется – он будто сливается в единое полотно, и нужно постоянно всматриваться и напрягать зрение, чтобы различать отдельные части и разбивать их в уме на сегменты.
г) Быстрый просмотр текста строки на другой языкеОтсутствует необходимость искать текст строки на другом языке, потому что напротив каждой строки есть колонка на другом языке. В нашем случае это японский и английский. Если у нас не будет лок-кита, то каждый раз придётся открывать дополнительный документ на другом языке и искать нужную строку.
д) Полезные комментарии от создателя лок-китаВо время создания лок-кита его составитель в своей колонке может отмечать различные уникальные ситуации, чтобы потом переводчик или редактор обратили на это внимание. Например, в каком-то диалоговом окне область для текста фиксированная, и нужно уложиться в определённое количество символов. Чтобы избежать проверки этого места, можно заранее прописать необходимое число символов, и переводчик адаптирует свой перевод. Кроме того, некоторые строки активируются особым образом – для их запуска нужно что-то сделать. Знание этой информации также может повлиять на перевод текста. Ещё бывают ситуации, когда по тексту неизвестно, что именно произошло или к какому объекту подошли персонажи, а комментарий с описанием поможет переводчику сориентироваться, что в очередной раз сведёт проверки во время тестирования к минимуму.
е) Возможность писать любое количество заметокЭта удобная функция есть только в лок-ките. Столбцов с заметками можно создавать сколько угодно. В то время как при работе в текстовом редакторе такой возможности нет, а заметки приходится хранить в отдельном файле.
Кроме того, сам лок-кит обеспечивает возможность быстрого создания сборок с учётом хронологического порядка строк. Это достаточно удобно, потому что как только переводчик осилил новую главу, то можно вставить новый текст в игровые ресурсы и проверить его непосредственно в игре. Соответственно, это удобно и для распространения демонстрационных сборок, когда прогресс нужно обновлять в соответствии с выполненным количеством процентов, либо по главам. Стоит ли говорить о том, что работа с текстом без хронологического порядка строк практически исключает возможность создания сборок по главам?
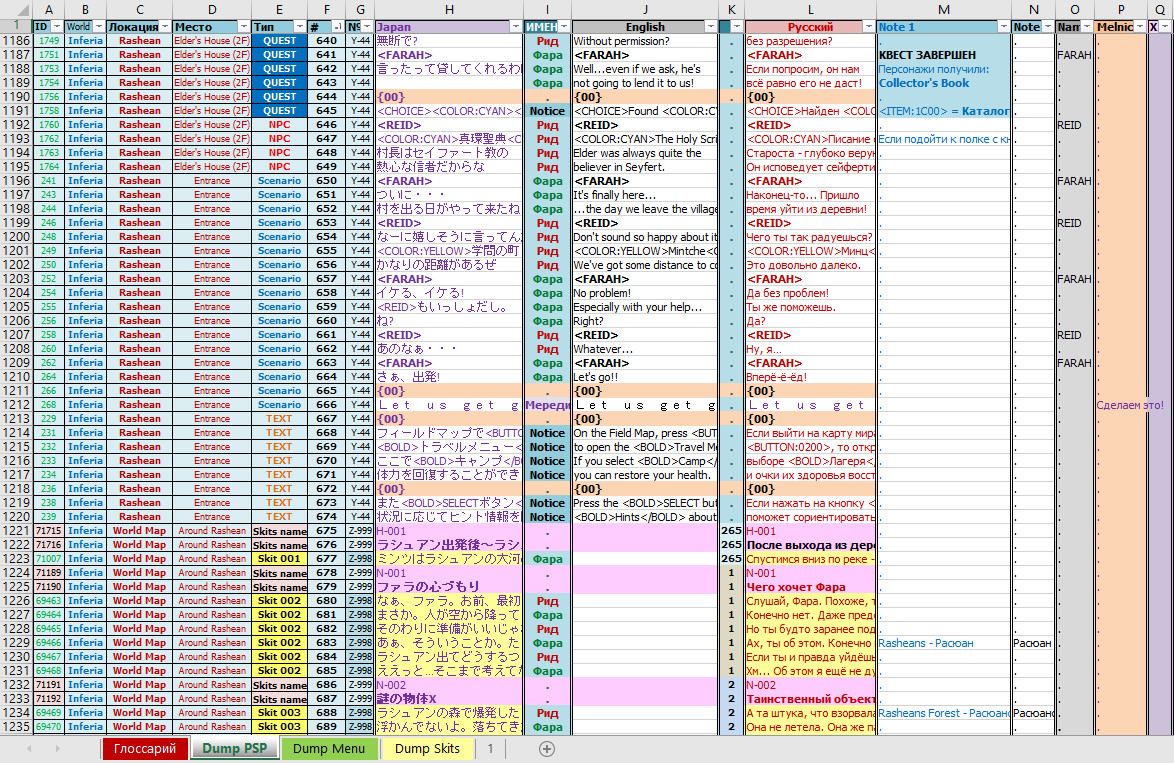
Надеюсь, я смог описать все стороны лок-китов так, чтобы вы смогли точно понять, на что они влияют сильнее всего и какой из этого можно извлечь результат. В довершение к данной главе хочу показать вам, как выглядит один из наших лок-китов к игре Tales of Eternia (PSP), над созданием которого работал я сам. Посмотреть его можно на изображении, приведённом ниже. Оформлялся он в виде электронной таблицы в Microsoft Excel. Если вам интересно «пощупать» его в самом приложении, то можете скачать документ по ссылке ниже. А уже в следующей главе на примере лок-кита по игре Tales of Rebirth (PS2) я наглядно покажу, что мне пришлось сделать, чтобы создать такой документ. Я попытаюсь оформить всё в виде инструкции для тех, кто отважится помочь нам в этом не лёгком деле с другими проектами.
Скачать #1https://temple-tales.ru/games/tor/data_design/files/Tales_of_Eternia_localization_kit_v1.0_by_Evil_Finalist.xlsxСкачать #2 (зеркало)https://disk.yandex.ru/i/j3kzCR14Ad-zYA