История русской локализации Tales of Rebirth (PS2)Глава 6. Разбор исполняемого файла ELF с помощью IDA Prohttps://vk.com/temple_of_tales_translationshttps://temple-tales.ru/games/tor/russian_localization.htmlЕсли попалась игра, в которой куча строк текста находится в исполняемом файле и с этим некому помочь, то, скорее всего, вам прямая дорога к таким инструментам обратной разработки, как IDA Pro или Ghidra. Для новичков это очень непростое погружение, и многое в этих приложениях может быть непонятным. Тем не менее часть из этого я попытаюсь объяснить, так как со всеми текстами в файле ELF Сказаний Перерождения мне пришлось поработать очень активно. И всё это для возможности гибких изменений, чтобы работать с текстом без ограничений по количеству символов на каждую строку.
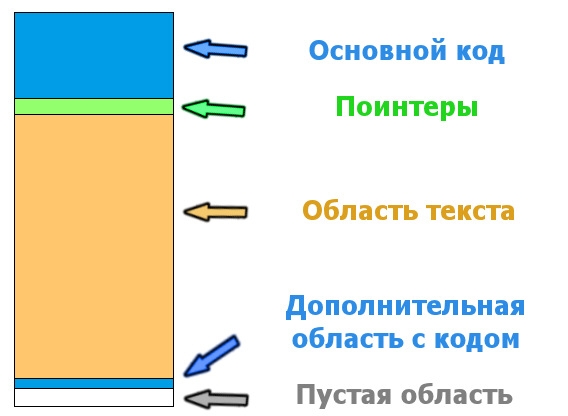
На изображении наглядная визуализация распределения поинтеров на блоки по разным местам исполняемого файла:

Если мы просто откроем исполняемый файл SLPS_254.50 в хекс-редакторе, то при беглом просмотре рано или поздно наткнёмся на блоки текста, которые распределены в хаотичном порядке близко к самому хвосту файла. На изображении выше я попытался визуально изобразить степень распределения текста и поинтеров в этой области. Все поинтеры скучкованы по разным блокам, а всего этих блоков более четырёх десятков. Кроме того, многие из них попадаются прямо посреди участков с записанными текстовыми данными. Всё это очень непросто отследить, высчитать, а также написать алгоритм для извлечения и вставки текста. В этом нам поможет комплекс нескольких программ. По началу мне советовали использовать специальное приложение под названием Kruptar авторства Джинни (
https://magicteam.net/index.php?page=programs). С одной стороны, я посчитал его слишком запутанным, а с другой – простым, так как программа имеет ряд ограничений, а созданный в ней проект привязан к своему файлу, в котором сконцентрированы все данные. Это, в свою очередь, накладывает ряд неудобств из-за невозможности внешней манипуляций на каждом шагу. Затем мне посоветовали поэкспериментировать с IDA Pro – эта программа умеет работать с архитектурой консолей PS1-2. Впоследствии я отказался от работы с IDA Pro и перешёл на более удобный мне способ извлечения и упаковки текста в исполняемых файлах. Тем не менее иногда я до сих пор открываю различные файлы PSX-EXE или ELF в IDA Pro для поиска каких-то данных, так как эта программа строит удобную карту взаимосвязей между различными функциями. Поэтому для начала я покажу вам, как искать поинтеры к строкам текстов в исполняемом файле с использованием IDA Pro и простого хекс-редактора.
Этап 1. Поиск любого текста в SLPS_254.50 через хекс-редактор и IDA Proа) Открываем любой хекс-редактор и ищем текст. К этому моменту у нас уже должен быть набит глаз для таких поисков. Возьмём для примера блок со строками текста, в котором находятся названия сценок. Первая строка начинается со смещения 0x1133E0, следующая с 0x1133F8 и т.д. О том, что именно этот блок является текстом, можно легко понять, если использовать на этой области преобразование кодировки текста, о которой я уже писал во втором этапе в четвёртой главе.
 б)
б) Теперь загружаем SLPS_254.50 в IDA Pro. Программа автоматически распознаёт файл как "ELF for MIPS", а среди перечня работы с архитектурой процессоров должна автоматически выбрать "MIPS little endian". Нажимаем "ОК" и ждём, как приложение просчитает взаимосвязи всех функций. После полного анализа вы услышите звуковое уведомление. Затем щёлкаем по вкладке "Hex View-1" и наблюдаем по головной части данных, что программа просчитала весь файл немного не так, как располагаются значения при открытии через хекс-редактор. Дело в том, что все смещения в IDA Pro указаны сразу с учётом расположения этих данных относительно оперативной памяти консоли. Поверьте, это весьма удобно для поиска поинтеров, которые имеют не фактический адрес. А ведь практически все поинтеры в исполняемом файле ELF именно такого типа. Теперь нам нужно найти здесь начало того же текста, как это было сделано в хекс-редакторе на смещении 0x1133E0. Для этого мы открываем в верхней строке вкладку "Search" и выбираем пункт "Sequence of bytes". Далее вводим все значения той самой строки, которую нашли через обычный хекс-редактор:
99 9c 9a 6e 9a 83 9a 8d 9a 5d 99 cd 9d 61 99 a6 99 cd 99 9d. Затем нажимаем "ОК" и, если всё написано верно, программа покажет расположение того самого текста.
 Этап 2. Поиск поинтеров в SLPS_254.50а)
Этап 2. Поиск поинтеров в SLPS_254.50а) Обратите внимание на выделенные красным цветом смещения строк в хекс-редакторе и IDA Pro на предыдущих двух изображениях. Имея на руках оба этих адреса, мы можем спокойно высчитать поправку для поиска будущих поинтеров. Для этого берём числовое значение смещения 0x2123E0 (IDA Pro) и вычитаем из него значение 0x1133E0 (хекс-редактор), а как результат получаем число поправки FF000. Теперь, когда нам известно смещение, где находится текст и число поправки, мы можем высчитать значение поинтера и адрес его расположения.
б) В этом и следующем пунктах я опишу метод поиска поинтеров через любой хекс-редактор. После того, как находим любую строку с текстом, запоминаем числовое значение смещения этой строки (в нашем примере это 0x1133E0), а затем к этому числу прибавляем поправку FF000 и получаем значение 002123E0. Если попытаться найти это значение через поиск, то у вас ничего не получится, потому что текущий вид этого значения имеет тип порядка байтов big-endian. Напоминаю, что принцип построения порядка байтов в поинтерах PS2 консоли имеет вид little-endian, а это значит, что необходимо развернуть полученное значение по байтам наоборот: 00 21 23 E0 >> E0 23 21 00.
 в)
в) Теперь, когда у нас на руках есть реальное значение самого поинтера, то его можно легко найти в исполняемом файле. Просто копируем 4 байта "E0 23 21 00" в строку поиска и жмём искать по всему файлу. Результатом должно быть одно найденное место, которое и будет являться поинтером. Запоминаем, что начало и конец этого поинтера находятся на смещениях 0xF5368 и 0xF536B.
 г)
г) Метод поиска поинтеров через IDA Pro гораздо проще, чем через хекс-редактор. Потому что вся разница сводится к тому, что на этапе 1 в пункте "б", найденный текст по первому байту уже подсвечивается смещением, которое можно спокойно вводить в поиск в пункте "Sequence of bytes". Только не забудьте во всплывающем окне поиска поставить галочку "Find all occurences", чтобы поиск работал по всему файлу.

Достаточно просто искать поинтеры таким вот способом, не правда ли? Если посмотрим на весь диапазон поинтеров, которые располагаются друг за другом выше от найденного указателя, то обнаружим, что все поинтеры, которые скучкованы в этом блоке, находятся в диапазоне от 0xF42A8 до 0xF536B. Всё, что находится за пределами этого диапазона – это уже совсем другие данные или другая группа поинтеров. Именно с этим диапазоном нам и нужно будет дальше работать. Потому что найти всё это одно дело, а составить алгоритм для правильной адресации, извлечения текстов с учётом разделителей, вставки изменённого текста с учётом пересчёта поинтеров и многого другого – совсем другая задача, которая требует использования совсем других подручных средств. В этом нам поможет приложение "abcde", которое я указал среди перечня сборника уникальных программ во второй главе, а также небольшое дополнение к нему под названием "ELF Text Injector", которое я специально заказывал у RikuKH3, чтобы облегчить себе работу по вставке текстов в ELF-файлы. Далее я поэтапно покажу, как пользоваться этими приложениями, которые не имеют графический интерфейс и в которых все настройки прописываются в основном в качестве числовых значений.
Этап 3. Установка Strawberry Perl, Python и работа с приложением abcdeа) Для начала необходимо установить Strawberry Perl. Это бесплатный дистрибутив на языке программирования Perl для операционных систем Windows. Он включает в себя всё для запуска и разработки Perl-приложений. Скачать его можно с официального сайта:
https://strawberryperl.com. Без этого abcde работать нормально не будет, так как приложение написано на этом языке. После этого требуется установить дистрибутив Python. "Он тоже бесплатный, но на другом одноимённом языке программирования. Его тоже можно скачать с официального сайта:
https://www.python.org/downloads. Один из моих знакомых Ethanol (уважаемый программист) написал специальный код на языке Python для работы с приложением abcde. Поэтому будем использовать его наработки.
 б)
б) Далее к этому пункту я прилагаю архив с приложением abcde v0.0.10, который включает в себя все готовые настройки для работы с нашим типом поинтеров. Его можно распаковать в любую папку.
Внимание!!! Для корректной работы программы и всех скриптов необходимо, чтобы путь к программе не содержал никаких пробелов. В противном случае приложение не будет извлекать текст и вставлять его обратно.Скачать #1https://temple-tales.ru/games/tor/data_design/files/abcde_v0.0.10.zipСкачать #2 (зеркало)https://disk.yandex.ru/d/CRbc-SWxnXHC-wКрасным я выделил файлы, которые были созданы дополнительно для работы с приложением, а зелёным - те, которые относятся к ресурсам игры: исполняемый файл и таблица с кодами для правильной идентификации кодировки игры.
 в)
в) Теперь нужно корректно настроить работу программы для извлечения строк текста. Сначала подготавливается TBL для работы с кодировкой игры (ToR.tbl). Об этом я уже рассказывал в четвёртой главе. Только разница с программой CODES в том, что abcde читает другой формат таблицы. Разделитель значений здесь другой. Кроме того, программа ругается на использование символов "<" и ">", а значит, в нашей таблице мы их опустим и заменим на "[" и "]" соответственно. Готовая таблица в формате TBL для приложения abcde прилагается в архиве, ссылка на который размещена в прошлом пункте.
 г)
г) Далее настраиваем работу с поинтерами через файл "!abcde_script_skits.txt". Все строки настроек я описывать не буду – пройдусь по основным, которые необходимы для понимания принципа работы. Этой базовой информации хватает для того, чтобы работать с исполняемыми файлами консолей PS1-2 и других аналогичных файлов, в которых поинтеры лежат в открытом виде.
 #GAME NAME: Tales of Rebirth
#GAME NAME: Tales of RebirthЗдесь указывается название игры. Данная строка ни на что далее не влияет, и является по своей сути простой меткой на случай, если у вас будет накоплено много файлов данного типа для разных игр.
#BLOCK NAME: SkitsВ этой строке прописывается название блока текста. А это на тот случай, если таких скриптов будет много в рамках одной игры. В принципе, можно даже указать название файла, если в нём всего 1 блок поинтеров и создавать другие нет надобности.
#POINTER ENDIAN: LITTLEС этого параметра начинается ввод важных данных, которые дают понять, с каким типом порядка байтов программе необходимо работать: big-endian или little-endian. В нашем случае это little-endian (особенность платформы PS2), но если бы мы работали с какой-нибудь игрой на ПК, то, скорее всего, пришлось бы указать big-endian. Приложение считывает синтаксис в этой строке только в таком виде:
BIG
LITTLE#POINTER TABLE START: $F42A8
#POINTER TABLE STOP: $F536BПомните, как был найден диапазон поинтеров для блока названия сценок? Об этом я писал на этапе 2 после пункта "г". Именно этот диапазон и нужно прописывать в этих двух строках. Одна из них указывает начало смещения, с которого начинается таблица поинтеров для данного блока, а вторая указывает самый последний байт крайнего поинтера в этом блоке. Приложение считывает синтаксис в этих строках только в таком виде:
$*****Вместо звёздочек нужно написать смещение.
#POINTER SIZE: $04Помимо типа порядка байтов, программа учитывает и размер поинтеров. Они бывают по 2 и 4 байта. Соответственно, в этой строке приложение будет считывать только следующий синтаксис:
$02
$04#POINTER SPACE: $00Если так случилось, что между поинтерами есть какое-то пространство, то эту особенность можно прописать в этой строке. Приложение будет учитывать эти пробелы между поинтерами, а если поинтеры идут друг за другом без дополнительного пространства, как в нашем случае, то необходимо указывать просто нулевое значение. Приложение считывает синтаксис в этих строках только в таком виде:
$**Вместо звёздочек нужно написать размер в байтах, которое будет соответствовать дополнительному пространству.
Наглядное представление пространства между поинтерами при просмотре через хекс-редактор на изображении ниже (поинтеры выделены голубым цветом):
 #BASE POINTER: $-FF000
#BASE POINTER: $-FF000Одно из первостепенных неудобств при работе с поинтерами в исполняемых файлах это то, что всегда нужно учитывать поправку. Разумеется, в этом приложении предусмотрен учёт разницы между фактическим расположением поинтеров в файле и оперативной памяти. Здесь приложение считывает синтаксис в этой строке только в таком виде:
$-*****Вместо звёздочек нужно написать размер поправки.
#TABLE: ToR.tblНу и напоследок стоит упомянуть таблицу кодов, которую здесь тоже нужно прописывать в виде названия файла. Именно на эту таблицу приложение и будет опираться во время извлечения строк с текстом.
д) Заранее подготавливаем файлы с командами для извлечения и вставки текста через командную строку:
Файл 1, извлечение!abcde_dump_skits.batperl abcde.pl -m bin2text -cm abcde::Cartographer "SLPS_254.50" "!abcde_script_skits.txt" Tales_of_Rebirth_dump_skits -s
pauseФайл 2, вставка!abcde_inception_skits.batperl abcde.pl -m text2bin -cm abcde::Atlas "SLPS_254.50" Tales_of_Rebirth_dump_skits.txt
pauseВсе файлы должны находиться в корневой папке приложения.
е) После того, как закончили готовиться к работе, копируем исполняемый файл игры в директорию программы и нажимаем пакетный bat-файл "!abcde_dump_skits.bat". После обработки получаем файл с извлечёнными строками текста "Tales_of_Rebirth_dump_skits.txt". Если всё сделано корректно, то вы увидите вот такое сообщение в командной строке:
 ж)
ж) Файл с извлечёнными строками текста будет выглядеть примерно так:

Первые несколько частей содержат дублирующую информацию из настраиваемого файла скрипта, но в немного изменённом виде, а чуть ниже уже идут строки с метками #JMP и //POINTER #0. С метками поинтеров всё просто. Для каждого поинтера есть свой индивидуальный блок с множеством сегментов. Здесь сразу указаны смещения поинтера и строки, порядковый номер и сами строки с извлечённым текстом.
Когда вы сделаете множество вот таких файлов с извлечёнными строками с текстом, то все блоки с поинтерами и прилагаемыми к ним данными можете копировать между собой или объединять в один файл без ограничений, а нумерация #0, #1, #2 и т.д. не будет мешать самому процессу работы. Данные номера – это просто заметка о порядковом номере извлечения. Так что в них нет ничего особенного. А вот что касается метки #JMP, то это вспомогательный сегмент, о котором стоит рассказать подробнее в следующем пункте, так как его роль очень важна.
з) #JMP – это отдельная настройка, которую программа высчитывает самостоятельно и которая потребуется нам дальше для обратной вставки изменённого текста. В извлечённом файле данная строка имеет вот такой вид:
#JMP($1133E0, $1195C0) // Jump to insertion pointВ скобках указан диапазон смещений между первым байтом первой извлечённой строки и последним байтом последней строки. Иначе говоря, данный интервал даёт нам представление о размере той области, в которой находятся извлечённые строки с текстом. Это очень полезная информация, и её нужно куда-то выписывать отдельно. Потому что, как я говорил в начале этой главы, в исполняемом файле есть несколько десятков отдельных блоков поинтеров, соответственно, и областей с текстом тоже. При обратной вставке текст нужно укладывать строго в те области, в которых изначально находился японский текст. Только таким образом в коде игры мы ничего не сломаем. Когда я активно занимался исполняемым файлом и идентифицировал все блоки поинтеров и области текста, то составил несколько строк с диапазоном, куда программе можно укладывать текст. Если кому-то интересно, то вот этот список:
112EA0;11332E
113DBC;1195C6
119890;11C8A6
11C8A8;11D99E
11D9A0;11E36E
11E370;11E88E
11E890;11F38E
11F3C0;11FCDE
11FCE0;1200B5
120228;1206C6
1206D8;120776
120778;12280E
122B30;12A63E
12A640;12AAAE
12AB28;12AFC6
12B0E8;12B15E
12B1A0;12BACE
12BAD0;12D0FE
12DCA0;12EBBE
12EBC0;12EF76
12EFF0;130A5E
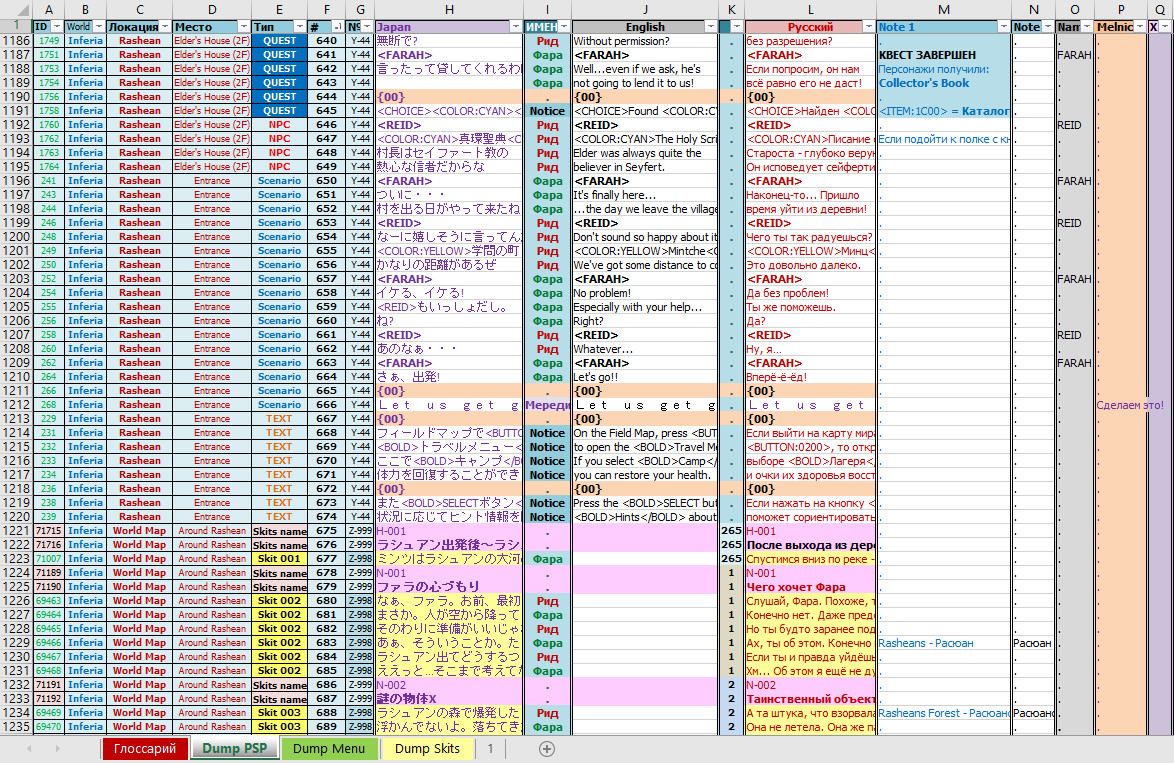
Внимание!!! При обратной вставке текста программа использует файл с извлечёнными строками текста "Tales_of_Rebirth_dump_skits.txt", а это значит, что во время этого процесса менять диапазон, прописанный в строке #JMP, можно как угодно. Это очень удобно, так как объём переведённого текста всегда отличается в большую или меньшую сторону. Возможность укладки текста в доступные области ограничена лишь вашими собственными нуждами. В общем, как вам удобно, так и выбирайте. Но к этому нужно подходить с умом, потому что когда областей мало, то расчёты сводятся к минимуму, а когда нужно работать с огромным количеством областей, то тут уже требуется провести достаточно большое количество расчётов.и) После того, как были извлечены все строки с названиями сценок в диапазоне 0xF42A8 - 0xF536B, их все можно переводить в этом документе ТХТ, но это достаточно неудобно, так как файл слишком большой, и в нём не так просто ориентироваться. А если учесть то, что таких файлов придётся сделать несколько десятков, то приходит понимание, что всё это нужно как-то систематизировать. В этом нам поможет Microsoft Excel. Для этого я создаю отдельную таблицу с фильтрами для столбцов, а также присваиваю каждой строке свой ID, чтобы всегда можно было развернуть порядок строк на обратный, как оно есть в исходном файле, а также сместить все лишние строки вниз, чтобы они не мешали во время процесса перевода. К этому пункту прилагаю готовый файл для экселя, а также на изображении ниже наглядно показываю, как выглядит текст до сортировки текста и после того, как всё упорядочено:
 Скачать #1https://temple-tales.ru/games/tor/data_design/files/Skits.xlsxСкачать #2 (зеркало)https://disk.yandex.ru/i/z-J4JIO7-zVtSwк)
Скачать #1https://temple-tales.ru/games/tor/data_design/files/Skits.xlsxСкачать #2 (зеркало)https://disk.yandex.ru/i/z-J4JIO7-zVtSwк) Как только текст переведён, можно отсортировывать все строки согласно корректным значениям алфавитного порядка по колонке ID, а затем выделить весь текст и скопировать его в файл с извлечёнными строками "Tales_of_Rebirth_dump_skits.txt".
 л)
л) Обратная вставка строк с текстом в исполняемый файл осуществляется через командную строку. Для этого просто запускаем пакетный bat-файл, о подготовке которого я упоминал ранее:
Файл 2, вставка!abcde_inception_skits.batperl abcde.pl -m text2bin -cm abcde::Atlas "SLPS_254.50" Tales_of_Rebirth_dump_skits.txt
pauseЕсли всё сделано корректно, то вы увидите вот такое сообщение в командной строке:
 Внимание!!! Всегда проверяйте числовые значения, которые прописаны в командной строке после вставки. Приложение прописывает там весь диапазон области для вставки, а также сколько байт было записано. Если общий объём вашего переведённого текста будет превышать установленный диапазон для вставки, то в командной строке программа уведомит вас о том, сколько байт было превышено.м)
Внимание!!! Всегда проверяйте числовые значения, которые прописаны в командной строке после вставки. Приложение прописывает там весь диапазон области для вставки, а также сколько байт было записано. Если общий объём вашего переведённого текста будет превышать установленный диапазон для вставки, то в командной строке программа уведомит вас о том, сколько байт было превышено.м) В завершении этого этапа хочу отметить, что перед тем, как вставлять текст обратно в исполняемый файл, необходимо отредактировать файл с таблицей кодов. Так как для извлечения текста нужен один набор кодов, а для обратной вставки он немного поменяется, потому что в файле шрифта игры при адаптации кириллицы приходится использовать многие коды для русских букв. Именно поэтому всегда нужно иметь наготове 2 файла с таблицей кодов: для японской версии и для русской.
Это далеко не всё. Ведь всегда можно улучшить и как-то оптимизировать процесс запаковки или вставки текста. В самом начале главы я упоминал про дополнительную программу "ELF Text Injector" авторства RikuKH3. Дело в том, что работа с abcde хоть и решает множество задач, но во время вставки текста всегда тянет за собой весь дистрибутив, а также не учитывает оптимизацию текста. Именно поэтому в какой-то момент мне захотелось облегчить процесс. Я заказал у RikuKH3 данную программу и кратко описал задачу: что именно мне требуется для работы с Tales of Rebirth, а также чтобы это по необходимости можно было применить к любым другим файлам. Использование данной программы полностью заменяет пункт "л" на этапе 3. Приложение вы можете скачать из таблицы сборника уникальных программ во второй главе. А уже саму настройку и использование программы я опишу на этапе 4.
Этап 4. Использование ELF Text Injector для оптимизации вставляемого текстаа) В первую очередь важно понять, что ELF Text Injector распознаёт синтаксис abcde и для вставки использует файл извлечённого текста "Tales_of_Rebirth_dump_skits.txt". Ничего заново настраивать не нужно. Кроме того, приложение также подхватывает таблицу кодов TBL. Всё, что требуется, это подготовить файл с командами для вставки текста через командную строку, а также создать дополнительный файл "tor_elftext.lst" со списком диапазона смещений, в которые будет укладываться текст. Выглядит этот файл со списком вот так:
 б)
б) Обратная вставка строк с текстом в исполняемый файл осуществляется через командную строку. Для этого просто запускаем пакетный bat-файл, о подготовке которого я упоминал в прошлом пункте:
!1_Text_Injector_RUN.bat@copy /y SLPS_254.50 SLPS_254.50_new > NUL
tor_elftext.exe -LittleEndian "tor_elftext.tbl" "!2_ELF_Russian_compiled.txt" "SLPS_254.50_new"
@pauseЕсли всё сделано корректно, то в командной строке вы увидите вот такое сообщение:

Как и в случае с abcde, данная программа уведомляет о том, сколько байт было записано из доступного диапазона.
в) Но это всё, по сути, тоже самое, что и при использовании самого abcde. А вот что гораздо важнее – ELF Text Injector делает оптимизацию текста и экономит место во время укладки в заданный диапазон. Для полного понимания плюсов этого алгоритма на нём стоит остановиться подробнее. Дело в том, что разработчики множества игр используют как раз-таки этот метод. Его суть заключается в том, что если в процессе перевода имеется две и более строки с одинаковым текстом, то есть дубликаты, то программа укладывает только одну строку, а все поинтеры содержат адрес к этой самой строке. В результате у нас не записываются остальные дублирующие строки, а значит, происходит экономия места. Если попытаться изобразить это в хекс-редакторе, то выглядеть это будет примерно так:




































































 "
"







 23.06.2024 - Релиз версии 0.33
23.06.2024 - Релиз версии 0.33